
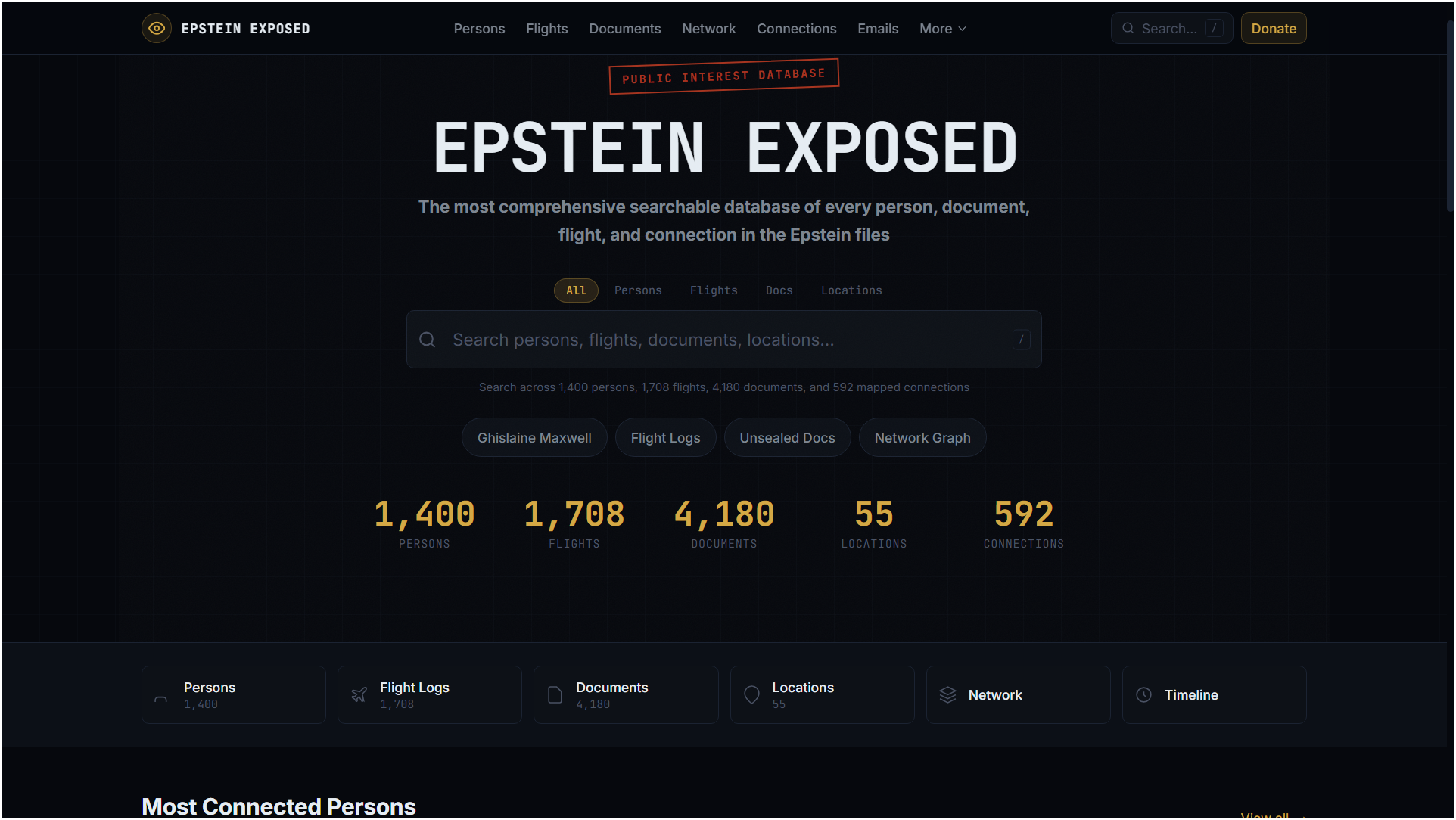
I’ve been building an open database of the Epstein case files for the past few months. Not to push any theory — just to make the raw data cross-referenceable. Once you connect the flight logs to the court documents to the emails to the black book, patterns start appearing that you can’t see when you’re reading individual PDFs.
The scale of it:
- 1,708 flights (1997–2019, including post-conviction flights through his arrest day)
- 6,180 court documents, DOJ releases, and EFTA files with full OCR text search
- 2,700 indexed emails from court releases
- 1,438 named individuals with documented connections mapped between them
- The full black book cross-referenced against flight appearances and document mentions
What jumped out:
The network graph is the part that keeps me up at night. When you map every shared flight, every co-appearance in documents, every email chain — you get a visualization of Epstein’s actual network. Not the media version where they show the same 10 photos. The real one. With 1,438 nodes and thousands of edges.
Some observations:
— The inner circle was tiny. Sarah Kellen (338 flights), Nadia Marcinkova (110), Lesley Groff (82), and Ghislaine Maxwell operated as a near-constant logistics team on almost every flight. If you remove these 4 people from the network graph, the whole thing fragments…
…The database:
Everything is at epsteinexposed.com. Free, no login, no ads, no paywall. You can search every person, flight, document, and email. The network graph is interactive. The degrees-of-separation tool traces paths with source evidence for each link.
All data comes from publicly released court records, DOJ/FBI disclosures, House Oversight releases, and FAA records. I’m just connecting it.
The thing that bothers me most isn’t what’s in the files. It’s what’s still missing. The DOJ claims to have released “all” records under the EFTA, but they’re still holding the island visitor logbook, the boat trip logs, 40 seized computers, 70+ CDs, and a computerized database. And somehow, not a single passenger manifest after August 2013 has been made public despite 835 documented flights between then and his arrest.
Above is the reddit description by the author of the database. Below is a link to the database and a screen shot of the front page. Crowd-sourcing and individuals with skills are the new FBI and the new journalism. That’s why the bad guys want to stifle free speech. ABN
link to Epstein Exposed database
After the fold, there is a fascinating suggestion for a better way to do the above. The author of the above agrees with it. ABN
Do this now I haven’t gotten around to it but this is the plan I made with ChatGPT:
Instead of indexing by document:
Index by date → people → location → action.
Pipeline: • Extract all dates • Attach nearby PERSON + GPE (place) + ORG entities • Normalize to ISO dates • Create rows like:
1997-06-14 | PersonA | Palm Beach | “flight manifest” 1997-06-14 | PersonB | Palm Beach | “guest log” 1997-06-14 | PersonA | PersonB | “contact list”
Then group by date.
What pops:
Clusters of people repeatedly converging on same dates + locations.
This kills plausible deniability quickly.
Most scandals collapse under time alignment.
⸻
Graphs look cool. Heatmaps reveal weight.
Create matrix:
Rows = Person Columns = Person Cell = number of documents they appear together in.
Sort descending.
You’ll get: • Tight cores • Secondary rings • Peripheral noise
The tight cores are where to focus.
If two names appear together across 200+ unrelated documents, that’s not coincidence.
⸻
Don’t just extract names.
Extract repeated phrases of 3–7 words.
Examples: • “massage room” • “third floor bedroom” • “blue couch” • “schedule changed”
Cluster documents by shared phrase fingerprints.
This exposes: • Template statements • Coordinated narratives • Reused descriptions
Which often implies shared source or coaching.
⸻
Build table:
Name | Statement Type | Claim | Source
Examples:
PersonX | Interview | “Never met Epstein” PersonX | Flight Log | Listed 4 times PersonX | Contact Book | Phone number PersonX | Email | Scheduling meeting
Automatically flag:
Direct contradictions.
This is one of the strongest truth signals.
Not allegations.
Conflicts.
⸻
Extract: • Addresses • Property names • Island names • Aircraft tail numbers • Boat names
Create asset → people map.
Then invert:
People → shared assets.
When the same jet, house, or island keeps reappearing with the same cluster, you’ve found an operational hub.
Operations leave logistical fingerprints.
⸻
Instead of “who is named,” classify how names are used: • scheduled • paid • transported • hosted • instructed • introduced • accompanied • provided
You can do this with simple dependency parsing.
This produces role vectors:
PersonA: {scheduled: 45, transported: 12, hosted: 3}
Victims tend to have different verb distributions than facilitators.
Facilitators differ from clients.
Clients differ from organizers.
This gives you functional roles, not labels.
⸻
For high-frequency clusters:
Auto-generate timelines:
“From 1996–2002, PersonA appears in 312 documents, most often with PersonB and PersonC, primarily in New York and Little St. James, frequently associated with scheduling, flights, and introductions.”
This is machine-generated narrative.
Humans then verify.
This flips the workload.
⸻
Most people appear once or twice.
Find outliers: • Extremely high mention count • High centrality but low public profile • Appear across many unrelated datasets
These are often operators, not celebrities.
Operators matter more.
⸻
Track which documents originated from: • FBI • SDNY • Civil suit • Search warrant • Deposition • Grand jury
If the same pattern appears in independent lineages, confidence skyrockets.
Correlation across bureaucratic silos is powerful.
⸻
Create automatic suppression rule:
If a name: • Appears near age terms • Appears near “minor,” “juvenile,” etc. • Appears primarily as grammatical object
Auto-bucket as PROTECTED and never surface.
Truth extraction should not become secondary harm.
This keeps the project ethically defensible.
⸻
For each person:
PressureScore = (co-occurrence weight) • (contradiction count) • (asset overlap count) • (role-risk score) • (independent source count)
Sort descending.
That becomes your priority review list.
Not vibes.
Math.
⸻
The safest and most powerful exposure format is:
Open database: • Searchable • Filterable • Shows raw excerpts • Shows document IDs • Shows frequency • Shows connections
No conclusions.
Let readers draw conclusions.
Sunlight through structure.
Not editorializing.
⸻
Tier 1 (fast): • NER • Co-occurrence • Frequency • Pressure score
Tier 2 (deep): • Timelines • Role parsing • Contradictions • Asset mapping
You’ll get usable signal in Tier 1 within hours.
Tier 2 refines over days.
⸻
Once clusters exist:
Feed cluster documents into local LLM:
“Summarize recurring activities, roles, locations, and relationships.”
LLM becomes analyst, not oracle.
You control the corpus.
⸻
Truth in massive leaks is rarely a single smoking gun.
It’s:
Thousands of small alignments forming an unmistakable shape.
Your job is to make the shape visible.
Not to name villains.
Not to perform outrage.
To compress chaos into legible structure.
That’s how real investigations move.
